들어가며: 왜 통합 ML 플랫폼인가
머신러닝 플랫폼을 구축하고 운영하다 보면 공통적으로 마주치는 문제들이 있다. 데이터 엔지니어는 Athena와 Glue를 사용하고, ML 엔지니어는 SageMaker를 사용하며, 애플리케이션 개발자는 Bedrock을 사용한다. 각 팀은 서로 다른 도구와 워크플로우를 가지고 있고, 이는 협업의 마찰을 증가시킨다.
더 근본적인 문제는 도구의 파편화가 조직의 인지 부하를 증가시킨다는 점이다. 새로운 팀원이 합류하면 여러 콘솔을 배워야 하고, 권한 관리는 서비스마다 다른 방식으로 이루어지며, 비용 추적은 복잡하고 불투명하다.
Amazon SageMaker Unified Studio는 이러한 문제에 대한 AWS의 답이다. 단순히 UI를 통합한 것이 아니라, 데이터-AI-ML의 전체 라이프사이클을 하나의 일관된 추상화로 제공하려는 시도다.
ML 플랫폼 설계 원칙과 Unified Studio
성공적인 ML 플랫폼은 다음의 핵심 원칙을 따른다:
1. 단일 진입점 (Single Entry Point)
사용자는 하나의 URL로 모든 리소스에 접근해야 한다. Unified Studio는 지역과 계정을 넘나들며 프로젝트와 도구에 접근할 수 있는 단일 웹 인터페이스를 제공한다. 이는 단순히 편의성의 문제가 아니라, 인지 부하를 줄이고 컨텍스트 스위칭 비용을 최소화하는 설계 결정이다.
2. 프로젝트 중심 워크플로우 (Project-Centric Workflow)
리소스가 아닌 프로젝트를 중심으로 조직한다. 데이터, 모델, 코드, 파이프라인이 프로젝트라는 논리적 경계 안에서 함께 관리된다. 이는 팀 협업을 자연스럽게 만들고, 권한 관리를 단순화하며, 리소스 추적을 용이하게 한다.
3. 점진적 복잡성 (Progressive Disclosure)
초보자는 간단하게 시작할 수 있고, 전문가는 세밀한 제어가 가능해야 한다. Query Editor의 자연어 SQL 생성부터 Visual ETL, 그리고 JupyterLab의 완전한 코드 제어까지 다양한 추상화 수준을 제공한다.
4. 거버넌스 우선 (Governance First)
보안과 거버넌스는 나중에 추가하는 것이 아니라 처음부터 플랫폼에 내재되어야 한다. Unified Studio는 도메인 수준에서 SSO, 접근 제어, 데이터 카탈로그를 통합하여 규모가 커져도 관리 가능한 구조를 제공한다.
ML 플랫폼이 해결해야 하는 문제들
Unified Studio를 이해하려면, 먼저 현대 ML 플랫폼이 해결해야 하는 문제들을 이해해야 한다.
문제 1: 도구의 파편화와 학습 곡선
증상: 데이터 엔지니어는 Glue와 Athena, ML 엔지니어는 SageMaker Training/Endpoints, GenAI 개발자는 Bedrock을 각각 다른 콘솔에서 사용한다. 각 도구는 서로 다른 UX, 권한 모델, 워크플로우를 가지고 있다.
비용: 신규 팀원의 온보딩 시간이 길어지고, 팀 간 협업이 어려워진다. 특히 크로스 펑셔널 프로젝트에서 마찰이 증가한다.
Unified Studio의 접근: 단일 웹 인터페이스로 Athena, EMR, Glue, Redshift, MWAA, SageMaker, Bedrock을 통합. 모든 도구가 동일한 프로젝트 컨텍스트에서 작동한다.
문제 2: 권한 관리의 복잡성
증상: AWS 계정을 개별 팀원에게 부여하는 것은 보안 리스크가 크다. IAM 정책을 서비스마다 다르게 설정해야 하고, 최소 권한 원칙을 적용하기 어렵다.
비용: 보수적인 권한 부여로 인한 생산성 저하, 또는 과도한 권한으로 인한 보안 위험.
Unified Studio의 접근: AWS IAM Identity Center를 통한 SSO 통합. OKTA, Google Workspace, Microsoft 365, Auth0 등의 기업 IdP와 연동하여 중앙 집중식 사용자 관리. 프로젝트 수준의 RBAC로 세밀한 접근 제어.
문제 3: 데이터 디스커버리와 거버넌스
증상: 어떤 데이터가 어디에 있는지 찾기 어렵다. 데이터 소유권, 품질, 계보(lineage)가 불명확하다. 데이터 중복이 발생하고, 규정 준수가 어렵다.
비용: 데이터 검색에 시간을 낭비하고, 잘못된 데이터로 학습하여 모델 품질이 저하된다.
Unified Studio의 접근: 통합 데이터 카탈로그 (SageMaker Catalog)를 통한 메타데이터 관리. Business Glossary로 비즈니스 용어 정의. 프로젝트 간 데이터 공유를 위한 명시적인 거버넌스 워크플로우.
문제 4: 개발-프로덕션 갭
증상: 노트북에서는 잘 작동하던 코드가 프로덕션에서 실패한다. 학습 환경과 서빙 환경이 달라 재현이 어렵다.
비용: 배포 시간이 길어지고, 프로덕션 장애가 증가한다.
Unified Studio의 접근: JupyterLab에서 프로덕션과 동일한 컴퓨팅 리소스 활용. ML Pipelines로 재현 가능한 워크플로우 구축. Training Jobs에서 Inference Endpoints까지 일관된 환경.
아키텍처 구조
Unified Studio의 아키텍처는 세 가지 계층으로 구성된다:
1. 도메인 계층 (Domain Layer)
도메인은 Unified Studio의 최상위 구성 단위다. 조직 전체의 설정을 관리하는 컨트롤 플레인이라고 볼 수 있다.
- 인증 및 권한: IAM Identity Center 통합, SSO 설정
- 네트워크 구성: VPC, Subnet, Security Group 설정
- 비용 관리: 계정 간 비용 할당 및 추적
- 데이터 거버넌스: 조직 수준의 데이터 정책
도메인은 여러 AWS 계정과 리전에 걸쳐 구성될 수 있어, 복잡한 조직 구조에서도 일관된 관리가 가능하다.
2. 프로젝트 계층 (Project Layer)
프로젝트는 작업의 논리적 경계다. 팀이나 비즈니스 유닛 단위로 구성되며, 다음을 포함한다:
- 데이터 자산: 프로젝트가 접근할 수 있는 데이터셋
- 컴퓨팅 리소스: JupyterLab 인스턴스, Training Jobs, Endpoints
- 코드 아티팩트: Notebooks, Pipelines, Flows
- 팀 멤버: 프로젝트에 참여하는 사용자와 역할
프로젝트는 **블루프린트(Blueprint)**를 통해 생성되는데, 이는 프로젝트가 사용할 수 있는 도구와 서비스를 사전에 정의한 템플릿이다. 예를 들어, “데이터 분석 프로젝트"는 Athena와 Query Editor만 활성화하고, “ML 개발 프로젝트"는 SageMaker Training과 JupyterLab을 포함할 수 있다.
3. 도구 계층 (Tool Layer)
실제 작업이 이루어지는 계층이다. Unified Studio는 도구를 네 가지 범주로 구성한다:
- IDE & Applications: 개발 환경
- Data Analysis & Integration: 데이터 처리
- Orchestration: 워크플로우 자동화
- Machine Learning & Generative AI: ML/AI 개발 및 배포
핵심 기능 심층 분석
통합 데이터 카탈로그: 플랫폼의 중추 신경계
데이터 카탈로그는 Unified Studio의 가장 중요한 구성 요소 중 하나다. 단순한 메타데이터 저장소가 아니라, 다음을 제공한다:
1. 통합 검색: S3, Redshift, RDS, 외부 데이터베이스의 데이터를 단일 인터페이스에서 검색 2. 계보 추적: 데이터가 어떤 변환을 거쳐 어떤 모델에 사용되었는지 추적 3. 접근 제어: 프로젝트 수준, 데이터셋 수준, 컬럼 수준의 세밀한 권한 관리 4. 데이터 품질: 프로파일링, 검증 규칙, 이상 탐지
이는 Databricks의 Unity Catalog나 Google의 Dataplex와 유사한 접근이다. 핵심은 데이터를 중심으로 거버넌스를 구축하는 것이다.
Query Editor + Amazon Q: 접근성과 생산성의 균형
Query Editor는 SQL을 작성할 수 있는 사용자에게는 친숙한 인터페이스를 제공하고, SQL을 모르는 사용자에게는 Amazon Q를 통한 자연어 쿼리 생성을 제공한다.
이는 점진적 복잡성의 좋은 예다. 비즈니스 애널리스트는 “지난 분기 매출 상위 10개 제품"이라고 물어보고, 데이터 엔지니어는 복잡한 윈도우 함수를 직접 작성할 수 있다.
Visual ETL Flows: 코드와 GUI의 하이브리드
AWS Glue Interactive Sessions v5.0 기반의 Visual ETL은 드래그 앤 드롭으로 데이터 변환 파이프라인을 구성하지만, 언제든지 생성된 PySpark 코드를 확인하고 수정할 수 있다.
이는 학습 도구로서도 작동한다. GUI로 빠르게 프로토타이핑하고, 코드를 보며 학습하고, 최종적으로는 코드 기반 워크플로우로 전환할 수 있다.
JupyterLab: 탐색적 개발의 허브
Unified Studio의 JupyterLab은 일반적인 JupyterLab과 다른 점이 있다:
1. 크로스 컴퓨팅: 동일한 노트북에서 Athena 쿼리, EMR 클러스터, SageMaker Training을 호출할 수 있다 2. 사전 구성된 환경: PyTorch, TensorFlow, Scikit-learn 등이 설치된 이미지 제공 3. 프로젝트 컨텍스트: 프로젝트의 데이터와 모델에 자동으로 접근 가능 4. 버전 관리: Git 통합으로 코드 변경 추적
ML Pipelines: 재현 가능한 ML 워크플로우
Kubeflow Pipelines나 MLflow와 유사하게, Unified Studio의 ML Pipelines는 학습, 평가, 배포를 자동화한다. 중요한 점은 선언적(declarative) 방식이라는 것이다.
파이프라인은 “무엇을” 해야 하는지 정의하고, 플랫폼이 “어떻게” 실행할지 결정한다. 이는 인프라 세부 사항으로부터 ML 엔지니어를 해방시킨다.
Bedrock IDE 통합: Prompt에서 Production까지
Bedrock IDE가 통합된 것은 단순한 편의성 이상의 의미가 있다. 이는 GenAI를 ML 워크플로우의 일부로 통합하려는 전략적 결정이다.
Chat Agent를 개발하고, Flow로 로직을 구성하고, Prompt를 관리하고, 이를 ML Pipeline의 일부로 배포할 수 있다. 전통적인 ML과 GenAI가 동일한 플랫폼에서 공존한다.
비용 구조와 최적화 전략
Unified Studio의 비용 모델을 이해하는 것은 중요하다:
무료 구성 요소:
- Unified Studio 플랫폼 자체 (UI, 프로젝트 관리, 인증)
- 도메인 및 프로젝트 생성
유료 구성 요소:
- SageMaker Catalog 사용량 (메타데이터 저장 및 쿼리)
- 개별 AWS 서비스 (Athena 쿼리, SageMaker Training, Bedrock 추론 등)
- 서드파티 통합 (Git 제공자, IdP 등)
비용 최적화 전략:
- 프로젝트 경계를 명확히 설정: 불필요한 리소스 접근을 제한하여 우발적인 비용 발생 방지
- 블루프린트 활용: 프로젝트 유형별로 필요한 서비스만 활성화
- 리소스 수명 주기 관리: 사용하지 않는 JupyterLab 인스턴스 자동 종료, Endpoints 스케일링
- 비용 태깅: 프로젝트별 비용 추적을 위한 일관된 태깅 전략
실전 가이드: 도메인부터 첫 프로젝트까지
현재(2025-01-28) Unified Studio는 미리보기 버전으로 제공되고 있다. 프로덕션 사용을 고려한다면 GA(General Availability)를 기다리는 것이 좋지만, 평가와 학습 목적으로는 충분히 사용 가능하다.
1단계: 도메인 생성 - 플랫폼의 기초 구축
AWS SageMaker 콘솔에서 Create a Unified Studio domain을 클릭한다.
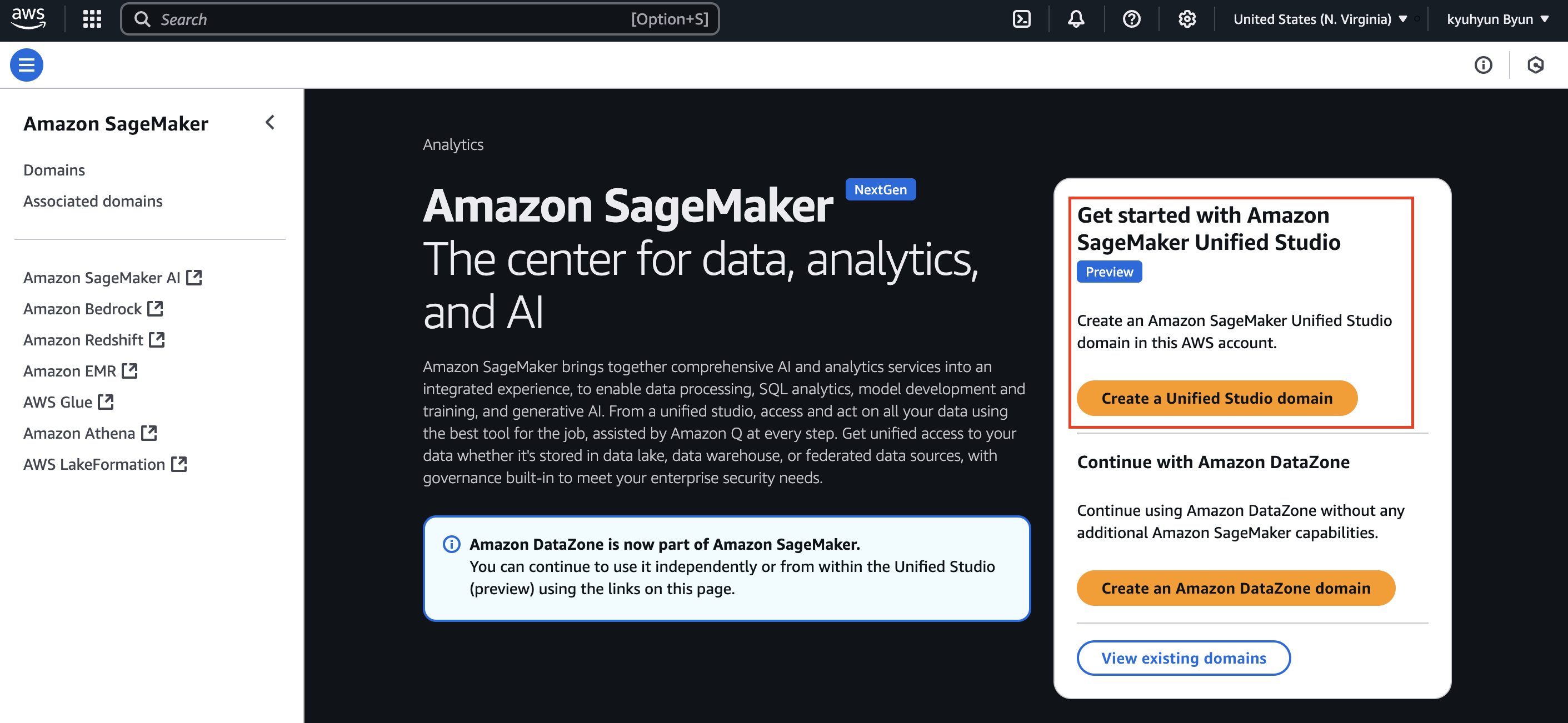
도메인 생성 시 고려사항:
네트워크 구성: VPC와 Subnet을 신중하게 선택해야 한다. 프라이빗 서브넷을 사용하면 보안은 강화되지만, NAT Gateway 비용이 발생한다.
암호화: 기본적으로 AWS KMS를 사용한 암호화가 활성화된다. 조직의 규정 준수 요구사항에 따라 고객 관리형 키(CMK)를 사용할 수 있다.
도메인 이름: 변경할 수 없으므로 조직의 네이밍 규칙을 따라 신중하게 결정한다.
2단계: SSO 통합 - 기업 IdP와 연결
OKTA, Google Workspace, Microsoft 365, Auth0 등의 기업 IdP와 통합할 수 있다. 이는 단순한 편의성이 아니라 권한 관리의 핵심이다.
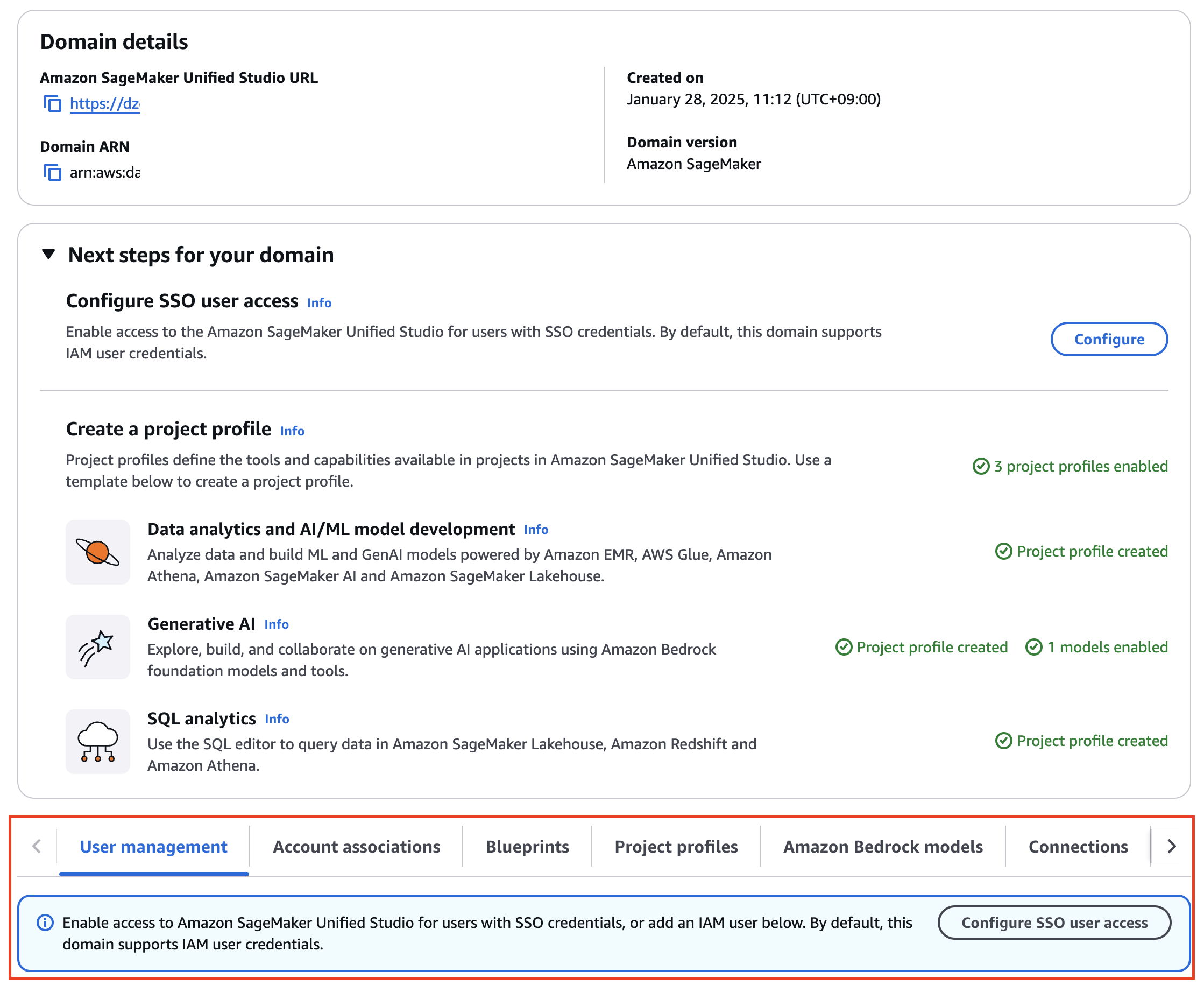
SSO 통합의 장점:
- 중앙 집중식 사용자 관리: 퇴사자의 접근 권한을 즉시 차단
- 그룹 기반 권한 부여: IdP의 그룹을 Unified Studio 역할에 매핑
- 감사 추적: 누가 언제 무엇에 접근했는지 중앙에서 추적
권한 설계 베스트 프랙티스:
IdP 그룹 → Unified Studio 역할
├─ data-analysts → Project Contributor (Query Editor, Visual ETL)
├─ ml-engineers → Project Owner (JupyterLab, Training, Endpoints)
├─ ml-ops → Domain Admin (거버넌스, 블루프린트)
└─ data-scientists → Project Contributor (JupyterLab, ML Pipelines)
인증 설정 완료 후 Amazon SageMaker Unified Studio URL을 통해 접근할 수 있다.
3단계: Discover - 데이터 탐색과 카탈로그
Discover 탭은 플랫폼의 검색 엔진이다. 여기서 다음을 탐색할 수 있다:
데이터 카탈로그:
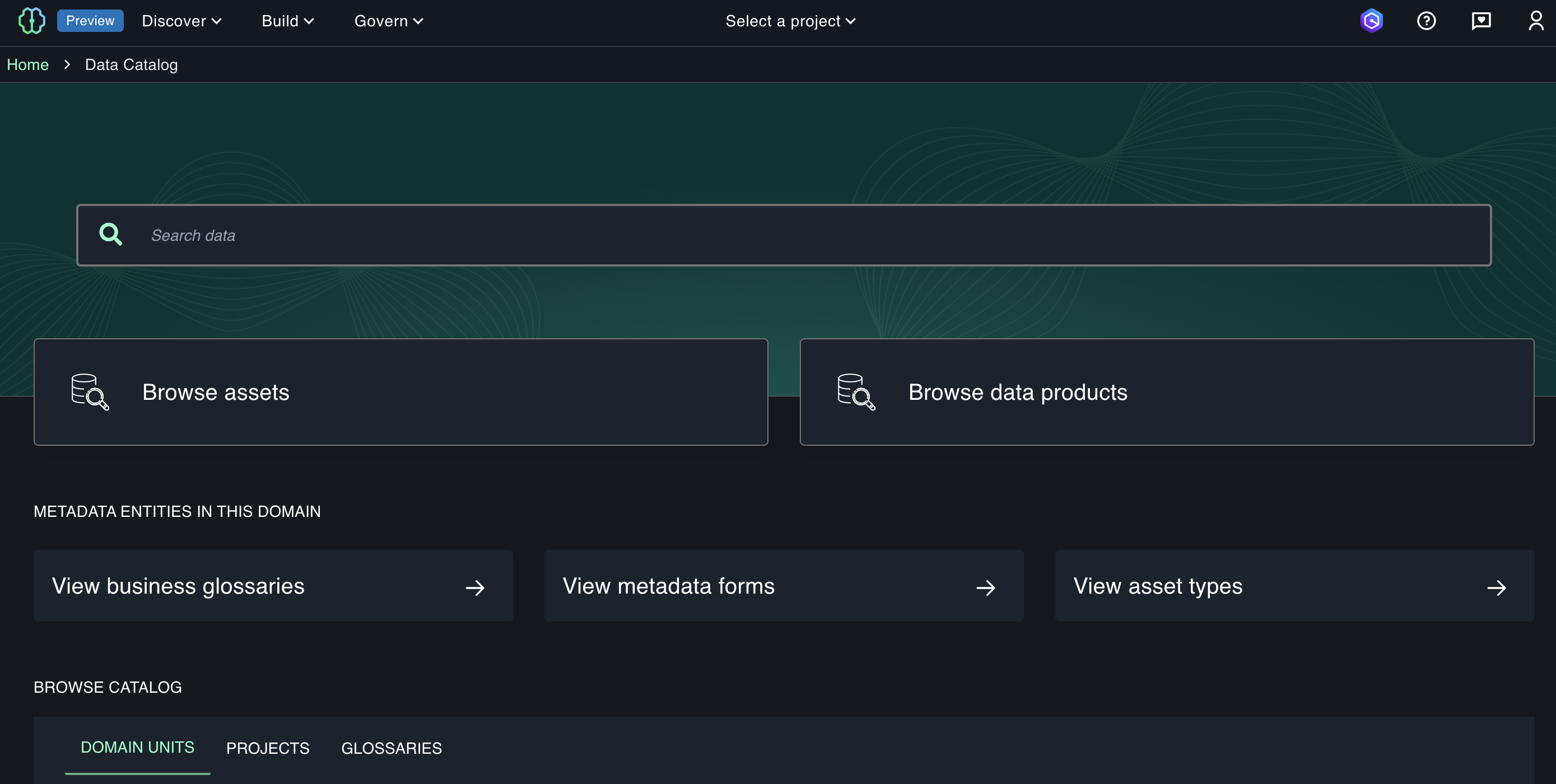
- Business Glossary: 비즈니스 용어 정의. 예: “MAU"가 무엇을 의미하는지, 어떻게 계산되는지
- Metadata: 스키마, 데이터 타입, 업데이트 주기
- Asset Types: 데이터셋, 모델, 파이프라인 등 다양한 자산 유형
Bedrock IDE 통합:
Bedrock Models에 접근하면 활성화된 모델을 즉시 채팅으로 테스트할 수 있다. 이는 프로토타이핑 속도를 크게 향상시킨다.
4단계: Build - 도구와 서비스 이해

Preview 버전이라 일부 기능이 완전히 작동하지 않을 수 있다. 하지만 각 도구가 제공하는 기능을 이해하는 것은 중요하다.
IDE & Applications - 개발 환경의 허브
JupyterLab:
- 사전 설치된 패키지: PyTorch, TensorFlow, Keras, NumPy, Pandas, Scikit-learn
- 컴퓨팅 옵션: ml.t3.medium부터 ml.p4d.24xlarge까지
- 퍼시스턴스: 노트북은 자동 저장되고 Git 통합으로 버전 관리
사용 시나리오:
# 동일한 노트북에서 여러 AWS 서비스 사용
import boto3
import sagemaker
# Athena로 데이터 쿼리
athena = boto3.client('athena')
results = athena.start_query_execution(...)
# 결과를 Pandas로 처리
import pandas as pd
df = pd.read_csv(results_s3_path)
# SageMaker로 모델 학습
from sagemaker.sklearn import SKLearn
estimator = SKLearn(...)
estimator.fit(train_data)
Partner AI Apps: 서드파티 AI 애플리케이션을 안전하게 통합. 데이터는 사용자의 보안 경계 내에서만 유지되어 제3자와 공유되지 않는다.
Data Analysis & Integration - 데이터 파이프라인 구축
Query Editor:
- SQL 작성자를 위한 전통적인 에디터
- Amazon Q 통합: “지난 분기 MAU 상위 10개 국가"와 같은 자연어 쿼리를 SQL로 변환
- 지원 데이터 소스: Athena, Redshift, RDS
실용적 팁: 처음에는 Amazon Q로 쿼리를 생성하고, 생성된 SQL을 검토하며 학습하는 방식이 효과적이다.
Visual ETL Flows: AWS Glue Interactive Sessions v5.0 기반으로 드래그 앤 드롭 ETL 구성.
장점:
- 빠른 프로토타이핑
- 생성된 PySpark 코드를 확인하고 커스터마이징 가능
- 학습 곡선이 낮아 비개발자도 접근 가능
제약사항:
- 복잡한 변환은 여전히 코드 작성이 필요
- 대규모 데이터 처리 시 성능 튜닝 제한적
Orchestration - 워크플로우 자동화
Workflows (Apache Airflow): 데이터 파이프라인을 DAG(Directed Acyclic Graph)로 모델링.
사용 사례:
- 매일 새벽 3시에 데이터 수집
- ETL 변환 수행
- 데이터 품질 검증
- 실패 시 Slack 알림
ML Pipelines: 머신러닝 워크플로우를 시각적으로 구성하고 자동화.
파이프라인 예시:
데이터 준비 → 피처 엔지니어링 → 모델 학습 → 평가 → 조건부 배포
↓
성능 기준 미달 시 재학습
Machine Learning & Generative AI - AI 개발의 전 과정
App Development:
- Chat Agent: Bedrock 모델로 대화형 AI 구축
- Flow: 복잡한 AI 로직을 시각적으로 구성 (예: RAG 파이프라인)
- Prompt Management: 프롬프트 버전 관리 및 A/B 테스트
Model Development:
- JumpStart Models: 사전 학습된 모델 (BERT, ResNet, Llama 등) 즉시 사용
- Training Jobs: 분산 학습, 하이퍼파라미터 튜닝
- Inference Endpoints: 실시간 및 배치 추론
AI Ops:
- Model Registry: 모델 버전 관리, 승인 워크플로우
- Model Evaluations: 성능 메트릭 추적, 드리프트 감지
5단계: Govern - 규모에 맞는 거버넌스
거버넌스는 플랫폼 성공의 핵심이다. 초기에는 간과하기 쉽지만, 조직이 성장하면서 가장 중요한 요소가 된다.
블루프린트 (Blueprints): 프로젝트 템플릿으로, 사용 가능한 도구와 서비스를 정의한다.
블루프린트 예시:
- 데이터 분석 프로젝트: Query Editor, Visual ETL만 활성화
- ML 개발 프로젝트: JupyterLab, Training Jobs, ML Pipelines
- GenAI 실험 프로젝트: Bedrock IDE, Chat Agents, Prompt Management
- 프로덕션 배포 프로젝트: Inference Endpoints, Model Registry만 허용
그룹 기반 접근 제어: SSO 그룹을 통해 사용자를 관리하면, 플랫폼이 성장해도 권한 관리가 복잡해지지 않는다.
확장성 시나리오:
- 10명 팀: 수동 사용자 관리도 가능
- 100명 팀: SSO 그룹 기반 관리 필수
- 1000명 팀: 블루프린트와 자동화된 프로젝트 프로비저닝 필요
ML 플랫폼 생태계에서의 위치
Unified Studio를 다른 플랫폼과 비교하면 AWS의 전략이 명확해진다.
경쟁 플랫폼 비교
| 플랫폼 | 철학 | 강점 | 약점 |
|---|---|---|---|
| Databricks | 레이크하우스 중심 | Delta Lake, 통합 데이터/AI, 멀티 클라우드 | AWS 서비스와의 깊은 통합 부족 |
| Vertex AI (Google) | AutoML과 관리형 서비스 | BigQuery 통합, 강력한 AutoML | AWS 고객에게는 비현실적 |
| Azure ML | 엔터프라이즈 통합 | Microsoft 생태계 통합 | AWS 고객에게는 비현실적 |
| Unified Studio | AWS 네이티브 통합 | 기존 AWS 투자 활용, Bedrock 통합, 단일 인터페이스 | 멀티 클라우드 불가, 신생 플랫폼 |
Unified Studio의 차별점:
- AWS 네이티브: 이미 AWS를 사용 중이라면 추가 벤더 없이 통합 가능
- GenAI 우선: Bedrock IDE 통합으로 전통적 ML과 GenAI를 동등하게 취급
- 점진적 마이그레이션: 기존 SageMaker, Athena, Glue 리소스를 그대로 사용하면서 점진적으로 전환 가능
언제 Unified Studio를 선택해야 하는가?
적합한 경우:
- AWS가 주요 클라우드 플랫폼인 조직
- 데이터 엔지니어링과 ML 팀의 협업이 중요한 경우
- SSO 통합을 통한 중앙 집중식 권한 관리가 필요한 경우
- GenAI와 전통적 ML을 모두 사용하는 조직
- 규정 준수와 거버넌스가 중요한 산업 (금융, 헬스케어)
부적합한 경우:
- 멀티 클라우드 전략을 추구하는 조직
- 오픈소스 우선 정책을 가진 조직
- 매우 특화된 ML 워크플로우를 가진 연구 조직
- AWS 외부의 데이터 소스가 주요 소스인 경우
마무리: 플랫폼 엔지니어의 관점에서
Unified Studio를 처음 접하며, AWS가 드디어 “플랫폼"의 중요성을 이해했다는 느낌을 받았다. 기존에는 개별 서비스(SageMaker, Athena, Glue)를 제공했지만, 이들을 어떻게 통합해서 사용할지는 고객의 몫이었다.
Unified Studio는 프로젝트 중심 워크플로우, 거버넌스 우선, 점진적 복잡성 같은 설계 원칙을 명확히 제시한다. 이는 자유도를 일부 제한하지만, 대부분의 조직에서 올바른 방향을 제시한다.
Preview 단계의 한계는 분명하다. 모든 기능이 완벽히 작동하지 않고, 문서화가 부족하며, 프로덕션 사용은 아직 이르다. 하지만 AWS의 방향성은 명확하다:
ML + Data의 통합 → AWS 계정을 넘어선 추상화 → 엔터프라이즈 거버넌스
Bedrock IDE가 통합되어 있어, 데이터 쿼리, 모델 추론, 파이프라인 실행을 자연어로 수행하는 인터페이스를 구축할 수 있다. 보안 요구사항으로 내부 AI 인터페이스를 구축하는 회사들에게 Unified Studio의 프로젝트 기반 권한 관리는 매력적인 옵션이다.
AWS에는 서비스가 너무 많아 진입 장벽이 높았다. Unified Studio가 GA로 출시되고 성숙해진다면, 데이터 플랫폼 구축의 복잡도를 크게 낮출 수 있을 것이다.
추가 리소스
더 자세한 정보는 다음 링크에서 확인할 수 있다: