Summary
각 사용자들의 연관 관계 분석을 위하여 GraphDB를 도입하려한다. 시작하기에 앞서서 GraphDB에 대해서 이해가 필요했다. 다음에서 GraphDB의 기본 내용을 담았다.
Graph Database란?
In computing, a graph database is a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data. A key concept of the system is the graph (or edge or relationship), which directly relates data items in the store. The relationships allow data in the store to be linked together directly, and in many cases retrieved with one operation.
This contrasts with relational databases that, with the aid of relational database management systems, permit managing the data without imposing implementation aspects like physical record chains; for example, links between data are stored in the database itself at the logical level, and relational algebra operations (e.g. join) can be used to manipulate and return related data in the relevant logical format. The execution of relational queries is possible with the aid of the database management systems at the physical level (e.g. using indexes), which permits boosting performance without modifying the logical structure of the database.
Graph databases, by design, allow simple and fast retrieval[citation needed] of complex hierarchical structures that are difficult to model[according to whom?] in relational systems. Graph databases are similar to 1970s network model databases in that both represent general graphs, but network-model databases operate at a lower level of abstraction[1] and lack easy traversal over a chain of edges.[2]
The underlying storage mechanism of graph databases can vary. Some depend on a relational engine and “store” the graph data in a table (although a table is a logical element, therefore this approach imposes another level of abstraction between the graph database, the graph database management system and the physical devices where the data is actually stored). Others use a key-value store or document-oriented database for storage, making them inherently NoSQL structures. Most[according to whom?] graph databases based on non-relational storage engines also add the concept of tags or properties, which are essentially relationships having a pointer to another document. This allows data elements to be categorized for easy retrieval en masse.
Retrieving data from a graph database requires a query language other than SQL, which was designed for the manipulation of data in a relational system and therefore cannot “elegantly” handle traversing a graph. As of 2017, no single graph query language has been universally adopted in the same way as SQL was for relational databases, and there are a wide variety of systems, most often tightly tied to one product. Some standardization efforts have occurred, leading to multi-vendor query languages like Gremlin, SPARQL, and Cypher. In addition to having query language interfaces, some graph databases are accessed through application programming interfaces (APIs).
[출처]: https://en.wikipedia.org/wiki/Graph_database
위 내용을 국내 서비스 파파고로 번역하면 다음과 같다.
컴퓨팅에서 그래프 데이터베이스는 노드, 가장자리 및 속성이 있는 의미 쿼리에 대해 데이터를 표시하고 저장하기 위해 그래프 구조를 사용하는 데이터베이스입니다. 시스템의 주요 개념은 저장소의 데이터 항목과 직접 관련된 그래프(또는 가장자리 또는 관계)입니다. 이 관계를 통해 저장소의 데이터를 직접 연결할 수 있으며, 대부분의 경우 한번의 작업으로 검색됩니다.
이는 관계형 데이터베이스 관리 시스템의 도움을 받아 물리적 기록 체인과 같은 구현 측면을 부과하지 않고 데이터를 관리할 수 있는 관계형 데이터베이스와는 대조됩니다. 관계형 쿼리의 실행은 데이터베이스의 논리적 구조를 수정하지 않고도 성능을 높일 수 있도록 하는 물리적 수준(예:인덱스 사용)의 데이터베이스 관리 시스템의 도움으로 가능합니다.
그래프 데이터베이스는 의도적으로 관계형 시스템에서 모델링 하기 어려운 복잡한 계층 구조를 단순하고 신속하게 복원할 수 있도록 해 줍니다. 그래프 데이터베이스는 일반 그래프를 나타내는 1970년대의 네트워크 모델 데이터베이스와 유사하지만, 네트워크 모델 데이터베이스는 더 낮은 수준의 추상화[1]로 작동하고 쉽게 편집할 수 없습니다.
그래프 데이터베이스의 기본 저장 메커니즘은 다를 수 있습니다. 일부는 관계형 엔진에 따라 다르며 표에 그래프 데이터를 “저장” 합니다(표는 논리적 요소이지만, 따라서 이 접근 방식은 그래프 데이터베이스, 그래프 데이터베이스 관리 시스템 및 실제 데이터가 저장된 물리적 장치 사이의 또 다른 수준 추상화를 부과합니다). 일부는 키 값 저장소 또는 문서 지향 데이터베이스를 사용하여 저장하기 때문에 기본적으로 NoSQL구조가 됩니다. 관계가 없는 스토리지 엔진에 기반하여 가장 많이[누구에게 기록하는가?]그래프 데이터베이스는 기본적으로 다른 문서에 대한 포인터를 가진 관계인 태그 또는 속성 개념을 추가하기도 합니다. 이를 통해 데이터 요소를 분류하여 일괄 검색이 용이하도록 할 수 있습니다.
그래프 데이터베이스에서 데이터를 검색하려면 SQL이외의 쿼리 언어가 필요합니다. SQL은 관계형 시스템의 데이터를 조작하도록 설계되었으며, 따라서 그래프 이동을 " 우아하게"처리할 수 없습니다. 2017년 현재, SQL과 같은 방식으로 일반적으로 채택된 단일 그래프 쿼리 언어는 없으며, 가장 많이 하나의 제품에 밀접하게 연관된 다양한 시스템이 있다. 몇가지 표준화 작업이 이루어져 Gremlin, SPARpd및 Cypher와 같은 멀티 벤더 쿼리 언어가 발생했습니다. 쿼리 언어 인터페이스와 함께 일부 그래프 데이터베이스는 API(응용 프로그램 프로그래밍 인터페이스)를 통해 액세스 됩니다.
먼저 간단하게 생각해보자. RDB의 탄생은 데이터를 적재하고 빠르게 조회하기 위해 탄생했다. 외래키와 같이 참조할 값을 넣어 JOIN, SubQuery, UNION 과 같은 기능으로 관계에 대해 질의할 수 있다. 하지만 이는 여러 ROW로 결과가 출력되며 서로 간의 관계를 보는 것에는 적합하지 않았다.
하지만 GraphDB는 이와 다른 관점에서 시작한다. 각 데이터는 고도로 연결되어 있고 그래프로 표현된다. 엣지라는 점에 연결되는 링크로 각 데이터를 구조화한다. 역사적으로 오일러의 그래프 이론으로 부터 나왔다. 공대를 나왔으면 오일러 공식 등 오일러라는 분에게 친숙한 느낌이 올 것이다. 그리고 이름을 들어보지 않았더라도 그래프 이론의 시작에 대해서 보면 한 번쯤은 들어봤던 이론이라는 것을 깨달을 것이다.
그래프 이론은 Königsberg Bridges 에서 시작되었다. 18세기에 다리를 중복하지 않고 모두 한 번씩 건너서 모든 다리를 건널 수 있을지 의문점을 가졌었다. 이는 가끔씩 볼 수 있는 한붓그리기와 같은 문제와 같은 것이었다. 이 문제를 풀기 위해서 단순화하는 과정이 필요하다. 육지를 연결해주는 다리를 Edge, 그리고 접점의 역할을하는 육지를 Ver-tex라고 한다. 한 접점에 연결되어 있는 다리의 수를 Degree라고 하는데, 홀수 Degree의 Ver-tex가 2개면 이 둘 접점이 시적점이거나 끝점이면 한붓그리기를 성공할 수 있다. 또한 모든 접점이 짝수 Degree를 갖을 때 한붓그리기가 가능하다.
그런데 이게 도대체 왜 GraphDB와 관련이 있을까? 이는 그래프 구조를 보여준 단적인 예였다. GraphDB는 이런 Graph 구조에 대해서 저장하는 Database일 뿐이고, 기존에 RDB로 표현하기 어려웠던 각 데이터간의 연결점들을 이어주고 표현해주는데 용이할 뿐이다. 만일 이런 데이터 Edge의 경중을 RDB로 표현하려면 굉장히 지저분한 쿼리를 볼 것이다. 각 파라미터를 Count를 하고 가중치를 주기 위해 새로운 데이터 View를 생성하던지 Table을 생성하고 또 이와 관계를 맺는 Join을 해야하고, 쉽지 않을 것이다.
하지만 이러한 데이터 간의 관계를 그래프형태로 표현해 줄 수 있는 GraphDB를 사용하면 달라진다.
솔직히 번역을 하더라도 감이 잘 안온다. 그럼 그림으로 보자.
다음 그림은 영화배우와 영화, 그리고 감독간의 연관관계를 표현한 것이다. 아름답지 않은가! 이렇게 연관관계가 표현될 수 있다니!
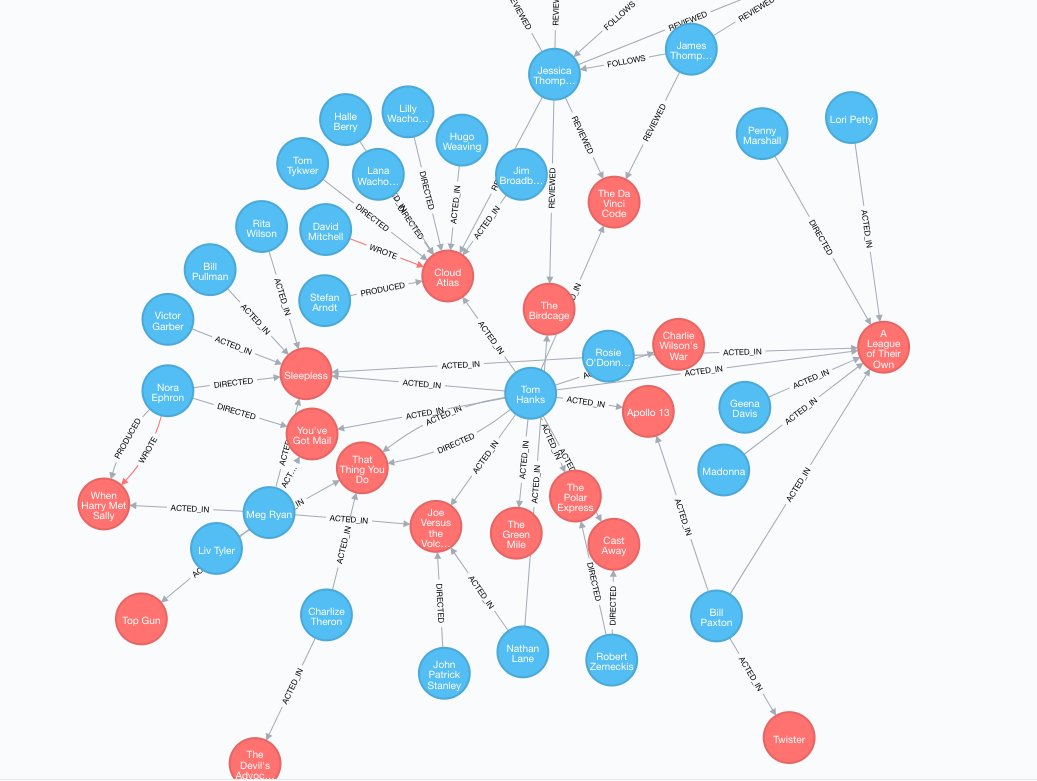
고찰
이런 GraphDB는 페이스북, 카카오, Netflix 등등 많은 기업에서 도입하여 사용중이다. 사용하는 알고리즘은 조금씩 다를 때도 있지만 표현하고자 하는 목적들은 비슷하다. 만약 저걸 SQL로 표현한다고 생각해보자. 솔직히 상상도 되지 않는다. 굉장히 힘든 작업이 될 것으로 예상된다. 하지만 GraphDB와 함께라면 Visualizing부터해서 손쉽게 표현될 수 있다.
물론 리스크는 존재한다.
GraphDB에 대해서 처음에 공부해야 하는 Learning Curve는 기본적으로 가져야만 하며, GraphDB에 대해 자료가 많지 않기 때문에 운영상 이슈에 대해 처리하는 것이 쉽지 않을 것이다. 또한 기존에 Collecting하는 Data Type이 GraphDB에서 어떻게 표현될지 고민해야 한다.
매일 쉽지 않은 선택을 한다. 새로운 공부를 시작하고 PoC를 진행하고, 실제 Production에 반영하기 전에 운영상의 이슈에 대해서 고민해본다. 그럼에도 불구하고 항상 같은 결론을 내린다. 도입해보는 것이다. 도입해보고 기존의 서비스와 느슨한 결합을 하도록 구성하여 문제시에는 바로 내릴 수 있도록 하는 것이다. 하나하나의 작은 경험이 나중에 큰 도약으로 이루어질 것이기 때문에 작은 시도도 끊임없이 해야 한다.
GraphDB를 선택하는 것을 잠깐이나마 멈칫했지만, 한 번 해보려고 한다. 다음번에는 GraphDB 사용기에 대해서 포스팅해봐야겠다.